Jersey Jazzman: Who Put the "Stakes" in "High-Stakes Testing"?
Peter Green has a smart piece (as usual) about Elizabeth Warren's position on accountability testing. Nancy Flanagan had some smart things to say about it (as usual) on Twitter. Peter's piece and the back-and-forth on social media have got me thinking about testing again -- and when that happens these days, I find myself running back to the testing bible: Standards for Educational and Psychological Testing:
"Evidence of validity, reliability, and fairness for each purpose for which a test is used in a program evaluation, policy study, or accountability system should be collected and made available." (Standard 13.4, p. 210, emphasis mine)
This statement is well worth unpacking, because it dwells right in the heart of the ongoing debate about "high-stakes testing" and, therefore, influences even the current presidential race.
A core principle of psychometrics is that the evaluation of tests can't be separated from the evaluation how their outcomes will be used. As Samuel Messick, one of the key figures in the field, put it:
"Hence, what is to be validated is not the test or observation device as such but the inferences derived from test scores or other indicators -- inferences about score meaning or interpretation and about the implications for action that the interpretation entails." [1] (emphasis mine)
He continues:
"Validity always refers to the degree to which empirical evidence and theoretical rationales support the adequacy and appropriateness of interpretations and actions based on test scores." [1] (emphasis mine)
I'm highlighting "actions" here because my point is this: You can't fully judge a test without considering what will be done with the results.
To be clear: I'm not saying items on tests, test forms, grading rubrics, scaling procedures, and other aspects of test construction can't and don't vary in quality. Some test questions are bad; test scoring procedures are often highly questionable. But assessing these things is just the start: how we're going to use the results has to be part of the evaluation.
Michael Kane calls on test makers and test users to make an argument to support their proposed uses of test results:
"To validate an interpretation or use of test scores is to evaluate the plausibility of the claims based on the test scores, and therefore, validation requires a clear statement of the claims inherent in the proposed interpretations and uses of the test scores. Public claims require public justification.
"The argument-based approach to validation (Cronbach, 1988; House, 1980; Kane, 1992, 2006; Shepard, 1993) provides a framework for the evaluation of the claims based on the test scores. The core idea is to state the proposed interpretation and use explicitly, and in some detail, and then to evaluate the plausibility of these proposals." [2] (emphasis mine)
As I've stated here before: standardized tests, by design, yield a normal or "bell-curve" distribution of scores. Test designers prize variability in scores: they don't want most test takers at the high or low end of the score distribution, because that tells us little about the relative position of those takers. So items are selected, forms are constructed, and scores are scaled such that a few test takers score low, a few score high, and most score in the middle. In a sense, the results are determined first -- then the test is made.
The arguments some folks make about how certain tests are "better" than others often fail to acknowledge this reality. Here in New Jersey, a lot of hoopla surrounded the move from the NJASK to the PARCC; and then later, the change from the PARCC to the NJSLA. But the results of these tests really don't change much.
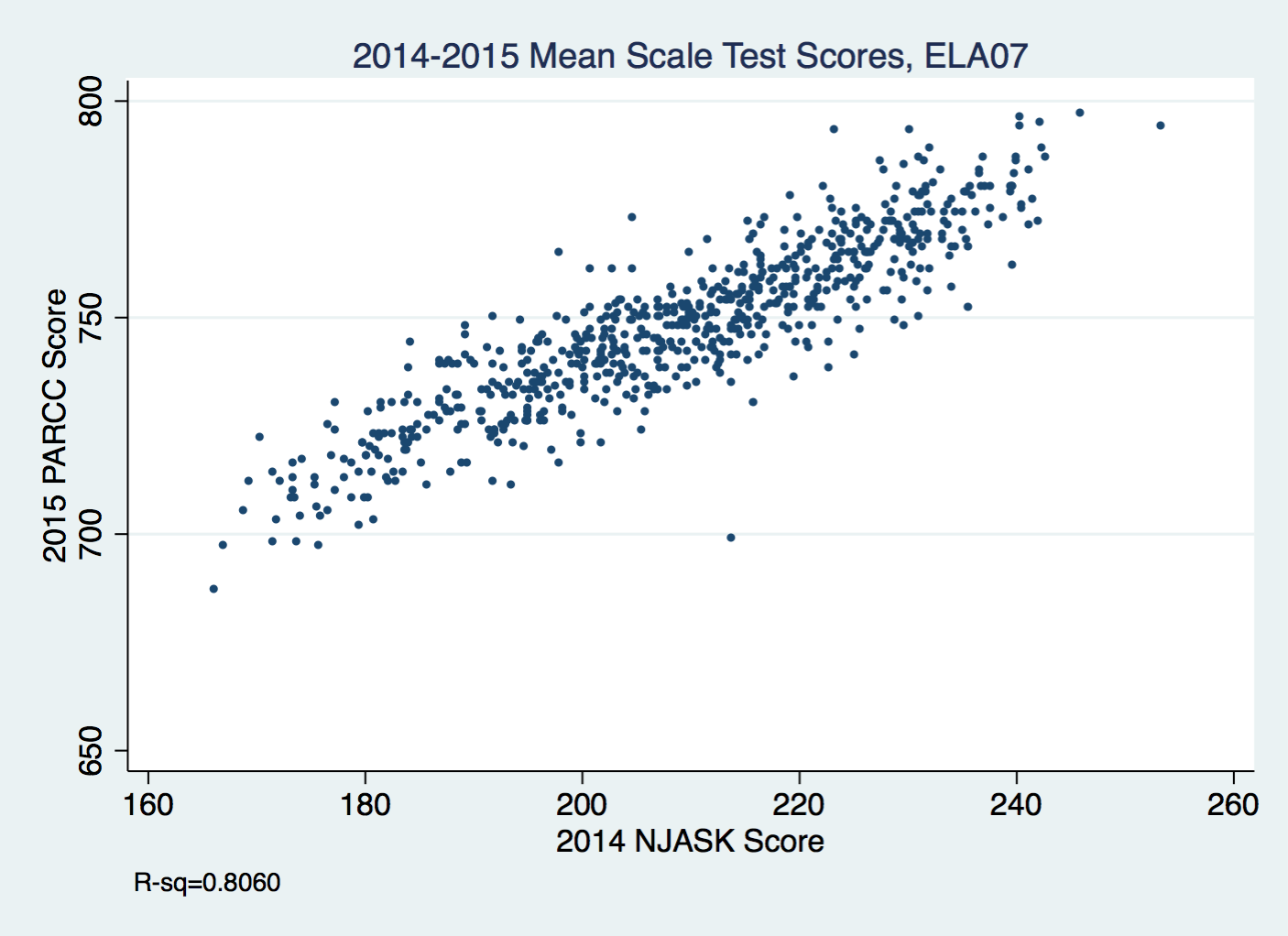
If you scored high on the old test, you scored high on the new one. So the issue isn't the test itself, because different tests are yielding the same outcomes. What really matters is what you do with these results after you get them. The central issue with "high-stakes testing" isn't the "testing"; it's the "high-stakes."
So how are we using test scores these days? And how good are the validity arguments for each use?
- Determining an individual student's proficiency. I know I've posted this graphic on the blog dozens of times before, but people seem to respond to it, so...
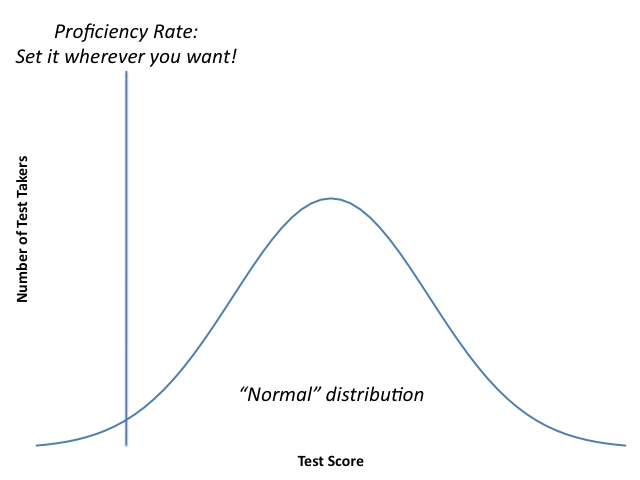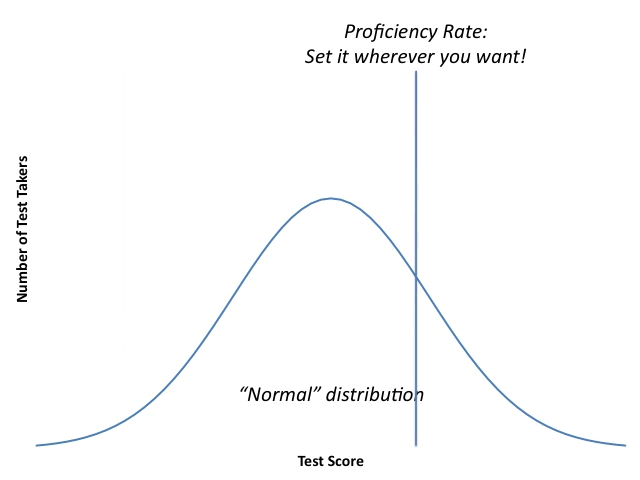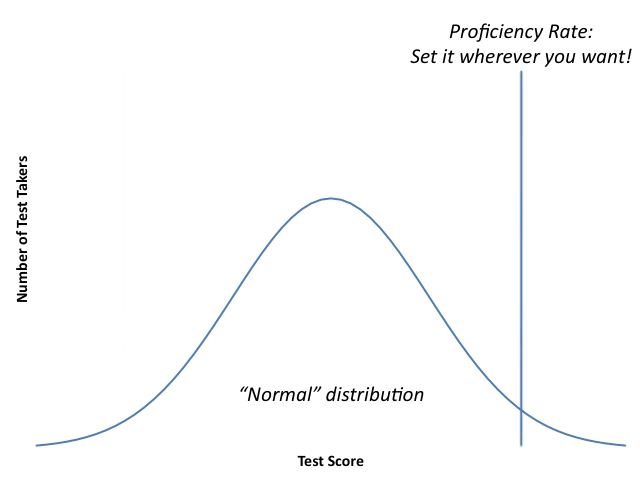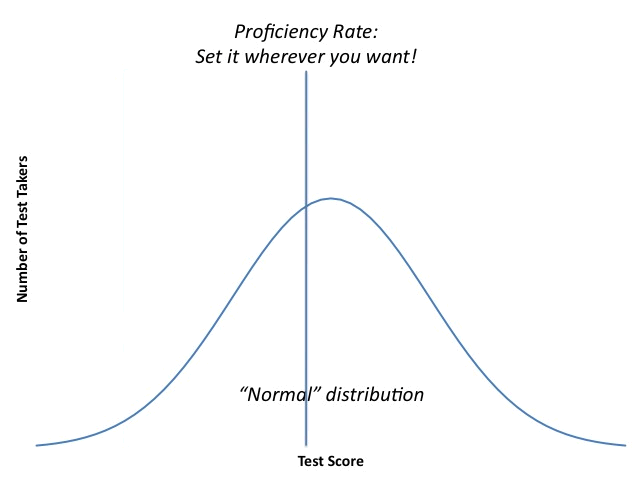
"Proficiency" is not by any means an objective standard; those in power can set the bar for it pretty much wherever they want. Education officials who operate in good faith will try to bring some reason and order to the process, but it will always be, at its core, subjective.
In the last few years, policymakers decided that schools needed "higher standards"; otherwise, we'd be plagued by "white suburban moms" who were lying to themselves. This stance betrayed a fundamental misunderstanding of what tests are and how they are constructed. Again, test makers like variation in outcomes, which means someone has got to be at the bottom of the distribution. That isn't the same as not being "proficient," because the definition of "proficiency" is fluid. If it isn't, why can policymakers change it on a whim?
I'll admit I've not dug in on this as hard as I could, but I haven't seen a lot of evidence that telling a kid and her family that she is not proficient -- especially after previous tests said she was -- does much to help that kid improve her math or reading skills by itself. If the test spurs some sort of intervention that can yield positive results, that's good.
But those of us who work with younger kids know that giving feedback to a child about their abilities is tricky business. A test that labels a student as "not proficient" may have unintended negative consequences for that student. A good validity argument for using tests this way should include an exploration of how students themselves will benefit from knowing whether they clear some arbitrary proficiency cut score. Unfortunately, many of the arguments I hear endorsing this use of tests are watery at best.
Still, as far as stakes go, this one isn't nearly as high as...
- Making student promotion or graduation decisions. When a test score determines a student's progression through or exit from the K-12 system, the stakes are much higher; consequently, the validity argument has to be a lot stronger. Whether grade retention based on test scores "works" is constantly debated; we'll save discussion for another time (I do find this evidence to be interesting).
It's the graduation test that I'm more concerned with, especially as I'm from New Jersey and the issue has been a key education policy debate over the past year. Proponents of graduation testing never want to come right out and say this in unambiguous terms, but what they're proposing is withholding a high school diploma -- a critical credential for entry into the workforce -- from high school students who did all their work and passed their courses, yet can't pass a test.
I don't see any validity argument that could possibly justify this action. Again, the tests are set up so someone has to be at the bottom of the distribution; is it fair to deny someone a diploma based on a test that must have low scoring test takers? And no one has put forward a convincing argument that not showing proficiency in the Algebra I exam is somehow a justification for withholding a diploma. A decision this consequential should never be made based on a single test score.
- Employment consequences for teachers. Even if you can make a convincing argument that standardized tests are valid and reliable measures of student achievement, you haven't made the argument that they're measures of teacher effectiveness. A teacher's contribution to a student's test score only explains a small part of the variation in those scores. Teasing out that contribution is a process rife with the potential for error and bias.
If you want to use value-added models or student growth percentiles as signals to alert administrators to check on particular teachers... well, that's one thing. Mandating employment consequences is another. I've yet to see a convincing argument that firing staff solely or largely on the basis of error-prone measures will help much in improving school effectiveness.
- Closing and/or reconstituting schools. It's safe to say that the research on the effects of school closure is, at best, mixed. That said, it's undeniable that students and communities can suffer real damage when their school is closed. Given the potential for harm, the criteria for targeting a school for closure should be based on highly reliable and valid evidence.
Test scores are inevitably part of the evidence -- in fact, many times they're most of the evidence -- deployed in these decisions... and yet their validity as measures of a student's probability of seeing their educational environment improve if a school is closed is almost never questioned by those policymakers who think school closure is a good idea.
Closing a school or converting it to a charter is a radical step. It should only be attempted if it's clear there is no other option. There's just no way test outcomes, by themselves, give enough information to make that decision. It may well be a school that is "failing" by one measure is actually educating students who started out well behind their peers in other schools. It may be the school is providing valuable supports that can't be measured by standardized tests.
- Evaluating policy interventions. Using test scores to determine the efficacy of particular policy interventions is the bread-and-butter of labor economists and other quant researchers who work in the education field. I rarely see, however, well-considered, fully-formed arguments for the use of test outcomes in this research. More often, there is a simple assumption that the test score is measuring something that can be affected by the intervention; therefore, its use must be valid.
In other words: the argument for using test scores in research is often that they are measuring something: there is signal amid the noise. I don't dispute that, but I also know that the signal is not necessarily indicative of what we really want to measure. Test scores are full of construct-irrelevant variance: they vary because of factors that are other than the ones test-makers are trying to assess. Put another way: a kid may score higher than another not because she is a better reader or mathematician after a particularly intervention, but because she is now a better test-taker.
This is particularly relevant when the effect sizes measured in research are relatively small. We see this all the time, for example, in charter school research: effect sizes of 0.2 or less are commonly referred to as "large" and "meaningful." But when you teach to the test -- often to the exclusion of other parts of the curriculum -- it's not that hard to pump up your test scores a bit relative to those who don't. Daniel Koretz has written extensively on this.
These are only five proposed uses for test scores; there are others. But the initial reason for instituting a high-stakes standardized testing regime was "accountability." Documents from the early days of No Child Left Behind make clear that schools and schools districts were the entities being held accountable. Arguably, so were states -- but primarily to monitor schools and districts.
I don't think anyone seriously thinks schools and districts -- and the staffs within them -- shouldn't be held accountable for their work. Certainly, taxpayers deserve to know whether their money is being used efficiently and effectively, and parents deserve to know whether their children's schools are doing their job. The question that we seem to have skipped over, however, is whether using standardized tests to dictate actions with high-stakes is a valid use of those tests' outcomes.
Yes, there are people who would do away with standardized testing altogether. But most folks don't seem to have a problem with some level of standardized testing, nor with using test scores as part of an accountability system (although many, like me, would question why it's only the schools and districts that are held accountable, and not the legislators and executives at the state and federal level who consistently fail to provide schools the resources they need for success).
What they also understand, however -- and on this, the public seems to be ahead of many policymakers and researchers -- is that these are limited measures of school effectiveness, and that we are using them in ways that introduce corrupting pressures, which makes schools worse. That, more than any problem with the tests themselves, seems to be driving the backlashing against high-stakes testing.
As Kane says: "Public claims require public justification." The burden of proof, then, is on those who would use tests to take all sorts of highly consequential actions. Their arguments need to be made clearly and publicly, and they have an obligation to not only demonstrate that the tests themselves are good measures of student learning; they also have to argue convincingly that the results should be used for each separate purpose for which policymakers would use them.
I would suggest to those who question the growing skepticism of high-stakes testing: go back and look at your arguments for their use in undertaking specific actions. Are those arguments as strong as they should be? If they aren't, perhaps you should reconsider the stakes, and not just the test.

[1] Messick, S. (1989). "Validity." In R. Linn (Ed.), Educational measurement (3rd ed., pp. 13–100). Washington, DC: American Council on Education.
[2] Kane, M. (2013). Validating the interpretations and uses of test scores. Journal of Educational Measurement 50(1), 1–73.
This blog post has been shared by permission from the author.
Readers wishing to comment on the content are encouraged to do so via the link to the original post.
Find the original post here:
The views expressed by the blogger are not necessarily those of NEPC.
